Salmón de piscifactoría vs. salmón salvaje: caso de uso de machine learning (redes neuronales)
- DATAMATE

- Aug 7, 2024
- 5 min read
Updated: Sep 21, 2024
El consumo de pescado, en particular de salmón, es recomendable para todas las edades debido a su fácil digestión y su alto contenido en ácidos grasos omega-3, vitaminas y minerales. El aumento de la población humana y los beneficios para la salud del consumo de pescado están impulsando la demanda de pescado.
Las prácticas pesqueras no sostenibles han agotado las poblaciones de peces silvestres, lo que ha generado problemas de seguridad alimentaria. En respuesta, se están ofreciendo peces de cultivo como una alternativa sostenible para satisfacer la creciente demanda de los consumidores.

Antes, los consumidores generalmente percibían que el pescado de piscifactoría era inferior al pescado silvestre. Sin embargo, investigaciones recientes indican que tanto el salmón de piscifactoría como el silvestre son igualmente valorados por la mayoría de los consumidores en los Estados Unidos, Europa y el resto del mundo.

La preferencia de los consumidores por el pescado salvaje frente al de piscifactoría está influida por diversos factores. Por ejemplo, las mujeres suelen preferir el pescado de piscifactoría debido a su participación en la cocina, mientras que las poblaciones costeras tienden a consumir menos pescado de piscifactoría en comparación con las poblaciones del interior.
Independientemente de las preferencias de los consumidores, consideremos un escenario en el que los estos buscan comprar salmón. Ya sea que estén caminando por el pasillo de un supermercado o comprando en línea ¿es posible que determinen si el producto ofrecido es pescado de piscifactoría o salvaje (una tarea de clasificación binaria) basándose únicamente en su apariencia externa, foto o imagen?
En un entorno industrial, como una planta de procesamiento de salmón, donde los errores humanos durante, por ejemplo, las operaciones de clasificación y empaque pueden tener consecuencias costosas en términos de tiempo y dinero ¿es posible determinar de manera rápida y automática con confianza si el producto manipulado es pescado de piscifactoría o salvaje basándose únicamente en imágenes o fotografías?
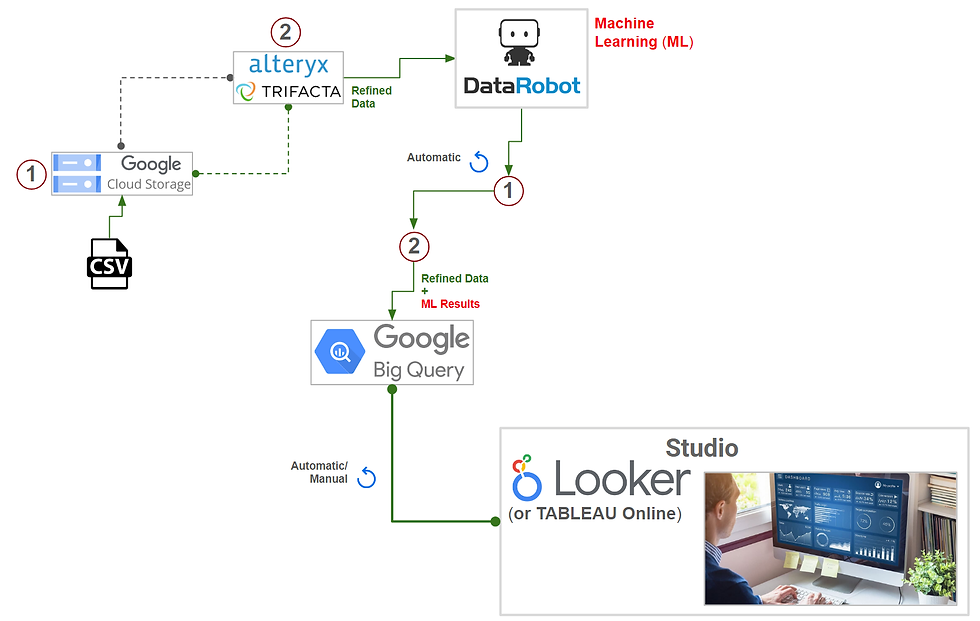
La respuesta a la pregunta anterior es "¡SÍ!". La imagen de arriba ilustra la arquitectura de alto nivel de una solución de análisis basada en la nube totalmente automatizada implementada en la Google Cloud Platform (GCP). Esta solución está diseñada específicamente para manejar esta tarea de clasificación binaria. La mejor opción para abordar este y otros problemas de aprendizaje automático es la plataforma DataRobot AutoML, como se mencionó en publicaciones anteriores.
El conjunto de datos utilizado para entrenar el algoritmo para este caso de uso proviene del portal Kaggle. Consiste en imágenes de salmón etiquetado como "FARMED" y "WILD". Las imágenes no han sido recortadas ni preprocesadas y fueron capturadas principalmente por fotógrafos aficionados en varios lugares, incluidos hogares, supermercados y restaurantes. El objetivo es evaluar la eficacia del flujo de trabajo propuesto en un escenario realista.


Para una tarea de machine learning que solo involucra imágenes como dato de entrada, el mejor método disponible en la Plataforma DataRobot es la tecnología Visual AI. De las docenas de modelos ejecutados y rankeados por la plataforma en este experimento, se eligió el modelo Elastic-Net Classifier (L2/Binomial Deviance). La imagen de arriba muestra el blueprint (plano) y su flujo de datos, así como una visualización de la arquitectura de red neuronal utilizada por este algoritmo para analizar las imágenes de entrada.
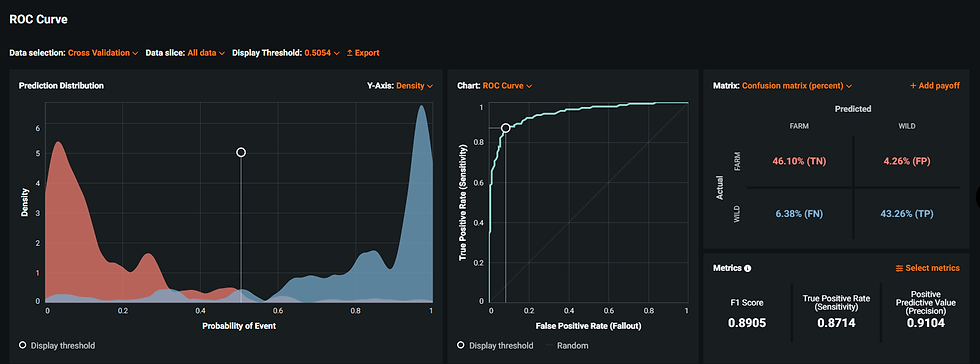
La figura a continuación muestra métricas para evaluar el desempeño del modelo: las probabilidades de los eventos están equilibradas uniformemente alrededor de 0,5 (aproximadamente la mitad "FARMED" y la otra mitad "WILD"); las métricas Fallout y Sensibilidad tienen valores satisfactorios (ver el gráfico al centro); y hay un bajo porcentaje de Falsos Positivos (FP) y Falsos Negativos (FN), 4,26% y 6,38%, respectivamente. El objetivo es tener un modelo más bien conservador, que busque emular el comportamiento humano lo mejor posible.
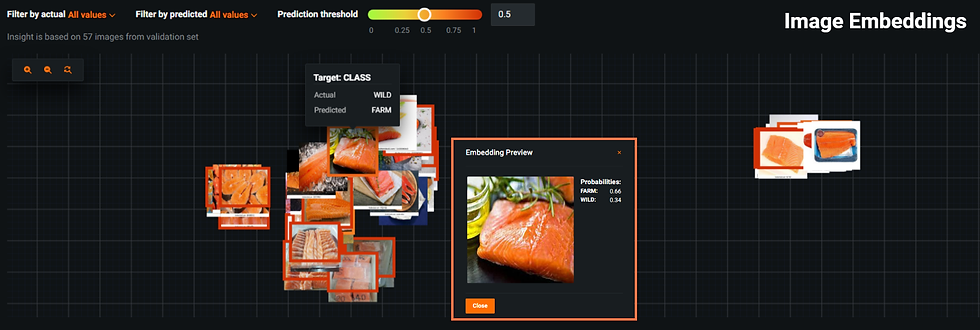
Para mostrar y comprender el modelo entrenado, Visual AI proporciona herramientas de Image Embeddings y Activation Maps. Las dos imágenes a continuación son ejemplos de incrustaciones de imágenes: en la primera, la clase real era WILD, pero se clasificó erróneamente como FARMED. Al hacer zoom (resaltado en color naranja), queda claro que la imagen de entrada contiene varias características ruidosas que podrían haber afectado negativamente a la predicción de la clase.
En la segunda figura, la clase real era FARMED, pero fué clasificada erróneamente como WILD. Al hacer zoom (resaltado en naranja), esta imagen también contiene características ruidosas que pudieran afectar negativamente a la predicción de la respectiva clase.
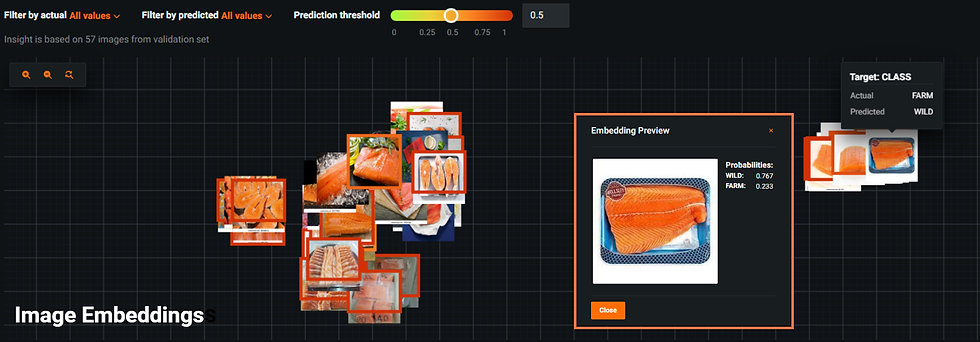
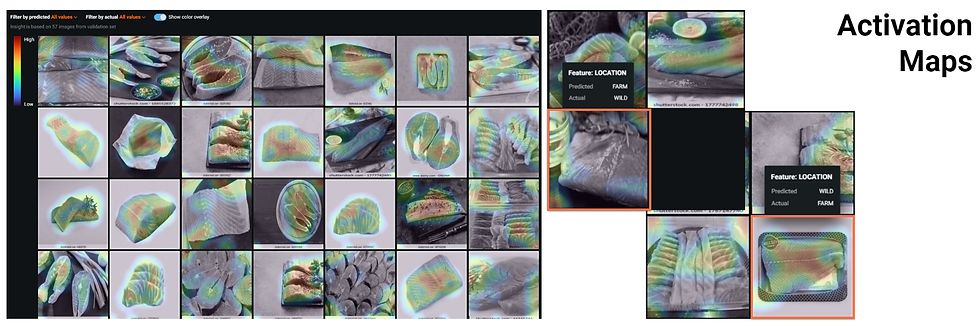
Por otra parte, la herramienta Activation Maps permite mostrar imágenes de muestra con resaltados de color que indican áreas de activación alta (rojo) y baja (azul). Ver la figura a continuación. El algoritmo de Deep Learning/red neuronal tuvo más en cuenta las áreas coloreadas en rojo para analizar las imágenes y realizar los cálculos. A la derecha de la figura, las mismas instancias mencionadas en el párrafo anterior se muestran nuevamente resaltadas en rectángulos naranja. Una vez más, si la foto de entrada contiene características indeseables, aumenta la probabilidad de que se clasifique incorrectamente incluso por algoritmos de Deep Learning/Redes Neuronales potentes y sofisticados.
Después de analizar y comprender el modelo, el siguiente paso es utilizarlo para clasificar y predecir las clases y determinar las probabilidades de un nuevo conjunto de datos de 80 imágenes sin etiquetas ni preprocesamiento (imagenes no incluidas en el entrenamiento del entrenamiento). Estas imágenes representan tanto salmones de piscifactoría como salmones silvestres. Aunque las clases ("FARMED"/"WILD") no están disponibles explícitamente, las mismas están embebidas en los nombres de los archivos y pueden ser extraídas.

Después de completar la tarea de clasificación con el nuevo conjunto de datos, se exportaron las etiquetas y probabilidades predichas. Luego, se combinaron con otras variables relevantes, como un link a la imagen y las clases reales extraídas de los 80 nombres de archivos de las imágenes de entrada. Además, se agregó una nueva columna para marcar la predicción como "right" si la etiqueta coincide con la clase real y como "wrong" si no lo hace.
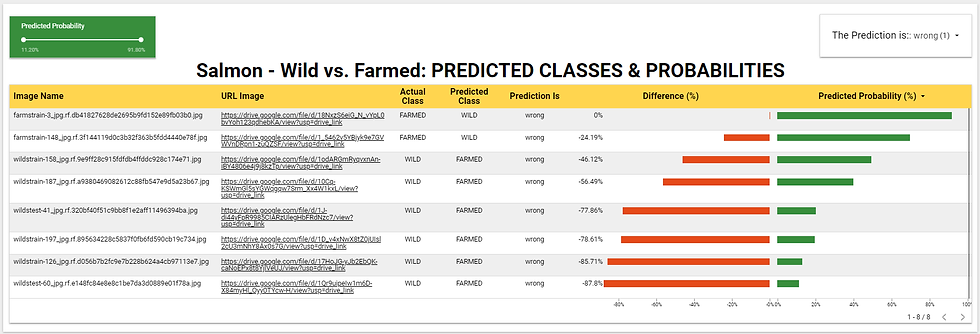
El conjunto de datos mencionado en el párrafo anterior se conectó a Google Looker Studio para crear una dashboard, que se muestra en la imagen de arriba. La dashboard cuenta con dos filtros que facilitan el análisis de resultados y la extracción de información crítica. Las barras verdes ilustran las probabilidades predichas, mientras que las barras rojas representan la Difference (%) negativa entre las clases reales y predichas. Un valor más negativo indica una mayor desviación (error) de la etiqueta predicha con respecto a la real.
En la figura anterior, solo se muestran las predicciones "wrong", es decir, cuando el modelo clasifica incorrectamente "FARMED" como "WILD" o viceversa. Esta clasificación errónea ocurrió solo en 8 de los 80 casos, es decir, 1 de cada 10, lo que representa solo una décima parte de la muestra. Esto último prueba el buen poder de predicción del modelo (conservador) que se está considerando. Sin duda, mejorar la calidad de los datos de entrada para el entrenamiento del modelo y realizar el ajuste fino del mismo, ciertamente, mejoraría sustancialmente sus capacidades predictivas.
Con base en el análisis y los resultados anteriores, es seguro afirmar que flujos de trabajo que incorporan la tecnología de Visual AI de DataRobot pueden ser implementados rápidamente en plantas de procesamiento de salmón y otros productos.
Esto incluye aplicaciones en procesos de clasificación y empaque, así como en varios otras tareas claves de las empresas, para imediatamente agregar valor y optimizar las operaciones, minimizando los efectos de posibles errores humanos que pueden tener consecuencias costosas en términos de salud, tiempo y dinero.
Angel Solutions (SDG) es miembro de Google Cloud Partner Advantage y socio de confianza de DATAMATE/DataRobot. Nuestros equipos están formados por profesionales altamente capacitados y equipados con las mejores AI-powered plataformas y herramientas para gestionar y brindar soluciones de manera eficaz a sus proyectos de datos, independientemente del tipo o volumen; soluciones para cualquier empresa, en particular la industria del salmón.
No dude en contactarnos directamente o a través de nuestro socio para obtener asistencia rápida y confiable.


Comments